
https://memodayoungee.tistory.com/157
[MSA] Spring Boot 프로젝트에서 MSA 실습하기(Spring Cloud) - 1
Spring 기반 프로젝트에서 MSA를 구현하기 위해서 Spring Cloud에 대해 알 필요가 있다. Spring Cloud : 개발자가 분산 시스템에서 일부 공통 패턴(예: 구성 관리, 서비스 검색, 회로 차단기, 지능형 라우팅,
memodayoungee.tistory.com
Spring Cloud를 활용해서 Eureka Server, API Gateway, Eureka Client 개발까지 완료했습니다.
이번에는 Kafka를 활용해서 Service끼리 통신하는 방법에 대해서 실습하겠습니다. RabbitMQ를 사용할 수 있겠지만, 개인적으로 진행하는 프로젝트에서 Kafka를 활용할 예정이라 Kafka로 실습합니다.
Kafka란?
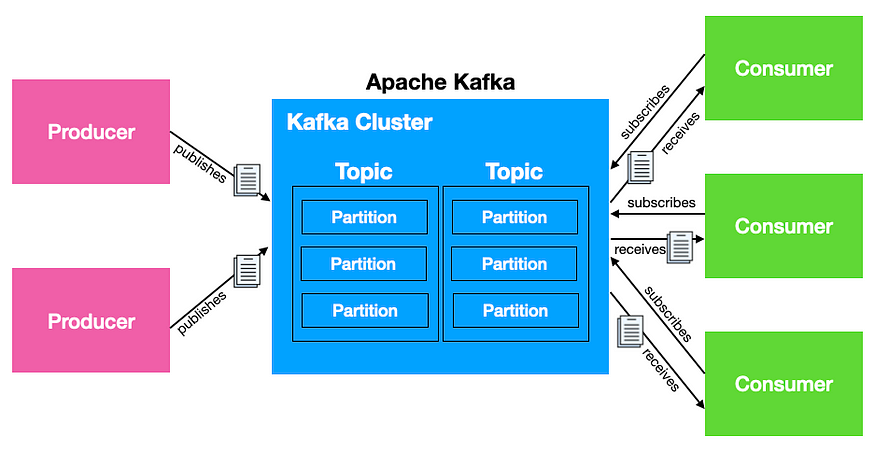
Apache Kafka: 분산 스트리밍 플랫폼으로, 대용량의 데이터 스트림을 처리하고 저장하는 데 사용된다. Kafka는 높은 처리량, 내고장성, 확장성을 갖추고 있어 대규모의 데이터 파이프라인 및 이벤트 스트리밍 애플리케이션을 구축하는 데 적합하다.
쉽게 말해 A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있는 플랫폼이다.
- 게시-구독 메시징 플랫폼(Publish/Subscribe): Kafka는 메시지 큐의 Publish/Subscribe 모델을 따른다. 프로듀서(출판자)가 메시지를 생성하고, 이를 컨슈머(구독자)가 구독하여 메시지를 받는다.
- 토픽(Topic): 메시지는 토픽 단위로 구성되며, 각 토픽에는 관련된 메시지들이 포함된다. 컨슈머는 특정 토픽을 구독하여 메시지를 수신한다.
- 파티션(Partition): 각 토픽은 하나 이상의 파티션으로 나누어진다. 이는 데이터를 여러 브로커에 분산하여 처리량을 높이고, 병렬 처리를 지원한다.
- 컨슈머 그룹(Consumer Group): 컨슈머는 그룹으로 구성될 수 있으며, 토픽의 각 파티션에 대해 한 컨슈머만이 메시지를 처리한다. 이를 통해 데이터를 병렬로 처리할 수 있다.
- 스프링 Kafka: Kafka를 사용하기 위한 Spring의 지원이 있는데, Spring Kafka는 Kafka를 더 쉽게 통합할 수 있도록 도와준다.
Kafka는 이벤트 메시지 브로커이다. 실시간 스트림, 메세지를 정책기반으로 보관, 처리량이 높고 퍼포먼스가 잘 나오기 때문에 빅데이터에 적합하다.
RabbitMQ는 메시지 브로커이다. 짧은 대기시간과 메시지 라우팅, 보안을 제공하기 때문에 좀 더 체계적으로 관리 하기 원할 때 사용된다.
쉽게 말해, 대규모 트래픽이 예상되고, 추후 확장이 예상되면, Kafka를 사용할 것. 그와 반대되는 상황이라면 RabbitMQ를 사용할 것.
MSA구조에서 Service끼리 통신할 수 있는 부분이 생길 수 있다. REST API를 통한 통신 외에도 메시징 시스템을 활용하여 서비스 간 비동기적인 통신을 구현할 수 있다. Kafka는 그러한 비동기 메시징 시스템 중 하나로서, MSA에서 서비스 간 통신을 위한 중앙 메시지 버스로 사용할 수 있다.
해당 실습에서는 프로듀서 역할을 하는 서비스가 어떤 데이터를 Kafka 토픽으로 전송할 것이다. 컨슈머 역할을 하는 서비스는 특정 토픽을 구독하고 해당 토픽으로부터 메시지를 받아 처리할 것이다.
이렇게 Kafka에 대한 이론만 봐서는 Kafka가 어떤 것인지 이해가 되지 않을 것이다. 실습을 통해서 Kafka가 무엇인지 찍먹해봅시다!
실습하기
Docker로 Kafka 실행하기
kafka는 zookeeper와 함께 실행되어야 합니다. 때문에 docker compose로 실행하는 것이 편리합니다.
카프카는 분산 애플리케이션의 한 종류로서 주키퍼를 코디네이션으로 이용하고 있습니다. 코디네이션 서비스 시스템은 분산 애플리케이션 관리를 위한 시스템입니다. Kafka 클러스터의 상태와 구성을 안정적으로 유지하고 관리합니다.
카프카 최신 버전에서는 주키퍼가 제거될 예정입니다. 메타데이터용 프로토콜인 카프카 라프트 또는 크라프트로 대체된다고 하네용 https://www.confluent.io/ko-kr/blog/removing-zookeeper-dependency-in-kafka/
docker-compose.yml 파일을 작성해봅시다.
같이 실습하던 지인이 docker compose 실행하는 부분에서 해매길래 사진 첨부합니다. 파일 생성 후 터미널로 실행하면 됩니다
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.12-2.5.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock1. ZooKeeper 서비스:
- 이미지: wurstmeister/zookeeper
- 컨테이너 이름: zookeeper
- 호스트 포트 2181을 컨테이너의 포트 2181과 연결하여 외부에서 ZooKeeper에 액세스할 수 있게 합니다.
2. Kafka 서비스:
- 이미지: wurstmeister/kafka:2.12-2.5.0
- 컨테이너 이름: kafka
- 호스트 포트 9092를 컨테이너의 포트 9092와 연결하여 외부에서 Kafka에 액세스할 수 있게 합니다.
- 환경 변수:
- KAFKA_ADVERTISED_HOST_NAME: Kafka가 사용하는 호스트 이름을 설정합니다.
- KAFKA_ZOOKEEPER_CONNECT: Kafka가 사용하는 ZooKeeper의 주소를 설정합니다.
- volums: Docker 컨테이너와 호스트 사이에 데이터를 공유하기 위한 역할을 합니다. volumes를 사용하면 컨테이너의 파일 시스템과 호스트의 파일 시스템 사이에 지속적인 데이터 저장소를 만들 수 있습니다.
작성이 끝났으면 터미널을 통해서 실행합니다.
docker-compose up -d
-d: 백그라운드에서 실행합니다.(daemon)
컨테이너가 잘 실행하고 있는지 콘솔로 직접 접근해볼 수 있습니다.
docker container exec -it kafka[컨테이너 이름] bash
Spring Boot 애플리케이션에 Kafka 적용하기
이전 https://memodayoungee.tistory.com/157 포스팅을 참고해주세요.
user service에서 이어서 진행합니다.
1) 의존성 추가
implementation 'org.springframework.kafka:spring-kafka'
build.gradle에서 카프카를 추가해줍시다.
2) application.yml 작성
spring:
application:
name: user-service
kafka:
consumer:
bootstrap-servers: localhost:9092
group-id: dev
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
Kafka Consumer 설정:
- bootstrap-servers: Kafka 브로커의 주소를 나타내며, 여러 브로커가 쉼표로 구분될 수 있습니다.
- group-id:
- Kafka Consumer Group의 식별자를 나타냅니다.
- 여러 Consumer가 같은 Group에 속하면 각각이 다른 파티션을 처리할 수 있습니다.
- auto-offset-reset:
- Consumer가 처음 실행될 때 또는 저장된 오프셋이 없을 때 오프셋을 설정합니다.
- earliest: 가장 이전의 메시지부터 소비를 시작합니다.
- latest: 가장 최근의 메시지부터 소비를 시작합니다.
- none: topic에 offset 정보가 없으면 exception을 발생시킵니다.
- key-deserializer, value-deserializer:
- Consumer가 읽어 들이는 메시지의 키와 값에 대한 역직렬화를 설정합니다.
- JSON이라면 JsonDeserializer를 사용하면 됩니다.
Kafka Producer 설정:
- bootstrap-servers:
- Kafka 브로커의 주소를 나타내며, 여러 브로커가 쉼표로 구분될 수 있습니다.
- key-serializer, value-serializer:
- Producer가 전송하는 메시지의 키와 값에 대한 직렬화를 설정합니다.
package com.example.userservice.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.boot.autoconfigure.kafka.KafkaProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import lombok.RequiredArgsConstructor;
@RequiredArgsConstructor
@Configuration
public class KafkaConfig {
private final KafkaProperties kafkaProperties;
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "dev");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // StringSerializer -> JsonSerializer
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
bean으로 등록해서 사용하는 방법입니다. yml 설정과 똑같은 설정이며, 방식만 다를 뿐입니다.
3) Producer
package com.example.userservice.kafka;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@RequiredArgsConstructor
@Service
public class KafkaProducer {
private static final String TOPIC = "order";
private final KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String message) {
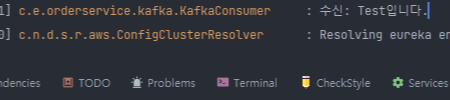
log.info("전송: {}", message);
this.kafkaTemplate.send(TOPIC, message);
}
}KafkaTemplate를 활용해서 카프카 브로커에 Topic과 함께 메시지를 전달합니다.
KafKaTemplate은 Spring Kafka에서 제공하는 클래스로, Kafka에 메시지를 전송하는 데 사용됩니다.
4) Consumer
서비스끼리 메시지를 주고 받는 것을 확인하기위해 order service를 만들어 consumer를 구현했습니다. order service 또한 차후 기능 구현 예정이라 이름만 저렇고... 사실 위의 user service와 다를 바 없이 별 다른 기능은 구현하지 않은 상태입니다.
package com.example.orderservice.kafka;
import java.io.IOException;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Service
public class KafkaConsumer {
@KafkaListener(topics = "order", groupId = "dev")
public void consume(String message) {
log.info("수신: {}", message);
}
}
@KafkaListener은 Kafka 메시지 리스너의 대상이 될 메소드를 표시하는 주석입니다.
groupId는 dev, topics은 order인 것만 해당 메서드에서 수신합니다.
5) Controller
package com.example.userservice.user;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import com.example.userservice.kafka.KafkaProducer;
import lombok.RequiredArgsConstructor;
@RequiredArgsConstructor
@RequestMapping("/users")
@RestController
public class UserController {
private final KafkaProducer producer;
@GetMapping
public String test() {
return "Hello!";
}
@PostMapping
public String sendMessage(@RequestParam("message") String message) {
this.producer.sendMessage(message);
return message;
}
}
쿼리스트링으로 받아오는 value 값을 카프카를 통해서 order service에 message 문자열을 전송합니다. 아주 간단한 Controller입니다.
5) 실행하기

API Gateway Port로 요청을 보냅니다.
터미널에서 kafka console에 접속하여 해당 명령어를 사용하면 어떤 메시지를 받았는지 알 수 있습니다.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic order(토픽이름)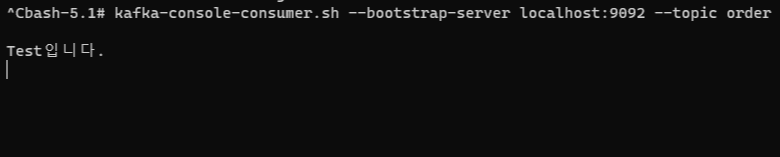
다음으론 아마도 쿠버네티스가 되지 않을까,.,, 싶습니다.
'DevOps' 카테고리의 다른 글
| [k8s] 쿠버네티스 란? (1) | 2023.12.03 |
|---|---|
| [MSA] Spring Boot 프로젝트에서 MSA 실습하기(Spring Cloud) - 1 (4) | 2023.11.25 |
| [아키텍처] 모놀리식 아키텍처 VS 마이크로 서비스 아키텍처(MSA) (0) | 2023.11.15 |
| [GitActions] Error: Gradle script '/home/runner/work/' is not executable. (0) | 2023.06.01 |
| netlify sass error (0) | 2022.04.18 |