
해시(Hash)란?
💡해시: 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 값이다. 해시를 이용하면 즉시 저장하거나 찾고자 하는 위치를 참조할 수 있으므로 더욱 빠른 속도로 처리할 수 있다. Key와 Value 한 쌍으로 존재하고 key값이 배열의 인덱스로 변환되기 때문에 시간복잡도가 O(1)에 수렴하게 된다.
💡해시 함수: 임의 크기 데이터를 고정 크기 값으로 매핑하는 데 사용할 수 있는 함수를 말한다.
성능 좋은 해시 함수들의 특징은 다음과 같다.
- 해시 함수 값 충돌의 최소화
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 균일하게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 해시 테이블 사용 효율이 높을 것
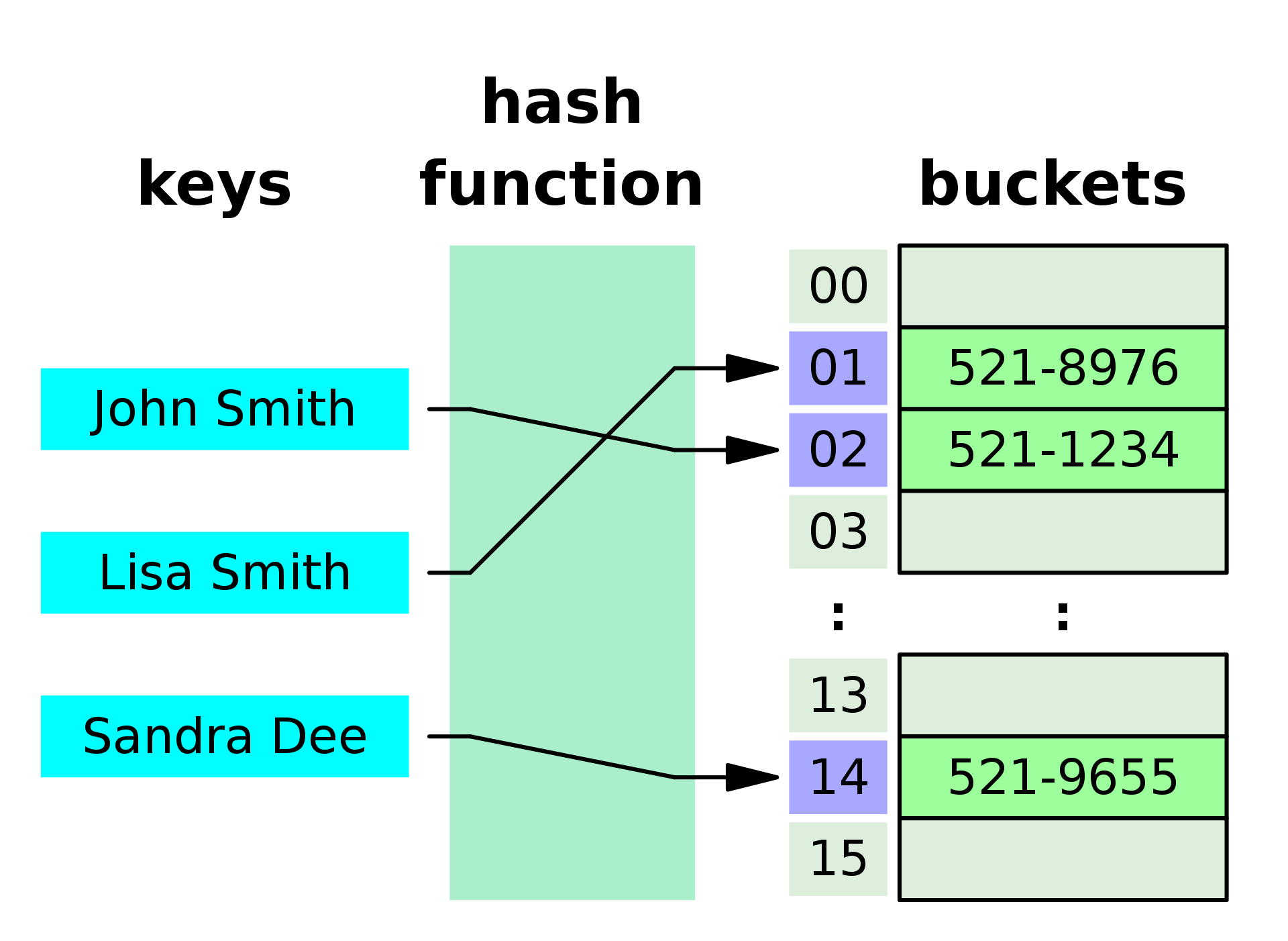
해시 테이블이란?
💡해시 테이블: (key, value) 한쌍으로 데이터를 저장하는 자료구조이다. 해시 함수를 사용하여 Key값을 해싱하여 정보를 찾거나 저장한다.
// 자바에서의 해시테이블
public class Main {
public static void main(String[] args) {
Hashtable<Integer, String> hashtable = new Hashtable<>();
hashtable.put(0, "김코딩");
hashtable.put(1, "김자바");
hashtable.put(2, "김알고리즘");
System.out.println(hashtable);
}
}
// 출력값
{2=김알고리즘, 1=김자바, 0=김코딩}Hashtable은 map의 구현체이다. 즉, map에서 사용하는 메서드를 Hashtalbe에서도 사용이 가능하다.
containskey() 라던가.. getOrDefalut라던가..
해시 값의 충돌
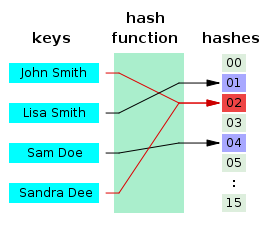
해시 함수가 서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황을 의미한다. 해시 함수가 무한한 가짓수의 입력값을 받아 유한한 가짓수의 출력값을 생성하는 경우, 비둘기 집 원리에 의해 해시 충돌은 항상 존재한다.
비둘기 집 원리: n개 아이템을 m개 컨테이너에 넣을 때, n>m이라면 적어도 하나의 컨테이너에는 반드시 2개 이상의 아이템이 들어있다는 원리를 말한다.
Birthday Paradox: 생일 패러독스란 366명의 사람이 모였을 때, 생일이 겹치는 사람이 최소 2명 이상이 된다는 것으로, 모든 경우의 수를 넘어서는 통계 표본이 존재할 때, 중복되는 값이 필연적으로 생길 수 밖에 없음을 말한다.
이 충돌 예방법에는 개별 체이닝, 오픈 어드레싱 기법이 있다.
개별 체이닝
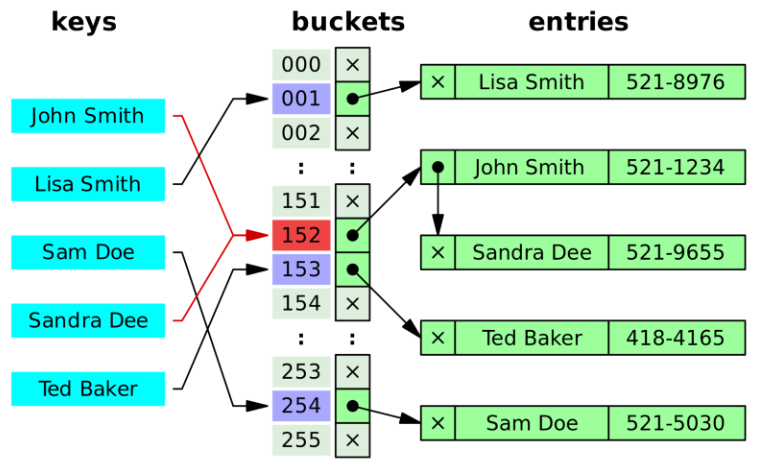
충돌을 허용하지만, 이를 최소화하기 위한 방법중 하나가 바로 체이닝 방식이다. 체이닝이란 이름 그대로 데이터들을 포인터를 이용해 서로 체인 형태로 엮어 나가는 것을 뜻한다. 따라서 최초로 저장된 데이터를 시작으로 그 이후의 값이 출력되는 데이터는 모두 연결 리스트의 형태를 취한다. 잘 구현한 경우 탐색은 O(1)이지만, 모든 해시 충돌이 발생했다는 가장을 한다면 O(N)이 될 수 있다. 자바 같은 경우 개별 체이닝 방식으로 구현되어 있다.
1. 키의 해시 값을 계산한다.
2. 해시 값을 이용해 배열의 인덱스를 구한다.
3. 같은 인덱스가 있다면 연결 리스트로 연결한다.
오픈 어드레싱

모든 데이터를 테이블에 저장하는 방식이다. 즉, 비어있는 해시를 찾아 빈 공간에 데이터를 삽입하게 된다. 사실상 무한정 저장할 수 있는 체이닝 방식과 달리, 오픈 어드레싱 방식은 전체 슬롯의 개수 이상은 저장할 수 없다. 이러한 특징으로 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장은 없다.
자바로 구현한 HashTable(체이닝 기법)
package hashtable;
import java.util.LinkedList;
public class HashTable {
class Node{
String key;
String value;
public Node(String key, String value) {
this.key = key;
this.value = value;
}
String getValue() {
return value;
}
void setValue(String value) {
this.value = value;
}
}
LinkedList<Node>[] data;
HashTable(int size){
this.data = new LinkedList[size];
}
int getHashCode(String key) {
int hashcode = 0;
for(char c : key.toCharArray()) {
hashcode += c;
}
return hashcode;
}
int convertHashCodeToIndex(int hashcode) {
return hashcode % data.length;
}
Node searchKey(LinkedList<Node> list , String key) {
if(list == null) {
return null;
}
for(Node node : list) {
if(node.key.equals(key)) {
return node;
}
}
return null;
}
void put(String key, String value) {
int hashcode = getHashCode(key);
int index = convertHashCodeToIndex(hashcode);
LinkedList<Node> list = data[index];
if(list == null) {
list = new LinkedList<Node>();
data[index] = list;
}
Node node = searchKey(list, key);
if(node == null) {
list.addLast(new Node(key, value));
}
else {
node.value = value;
}
}
String get(String key) {
int hashcode = getHashCode(key);
int index = convertHashCodeToIndex(hashcode);
LinkedList<Node> list = data[index];
Node node = searchKey(list, key);
return node == null ? "Not Found" : node.value;
}
}
Reference
http://wiki.hash.kr/index.php/%ED%95%B4%EC%8B%9C%EC%B6%A9%EB%8F%8C
http://wiki.hash.kr/index.php/%ED%95%B4%EC%8B%9C#.EB.AC.B4.EA.B2.B0.EC.84.B1
'Algorithm > 자료구조 개념' 카테고리의 다른 글
| [자료구조] 04. 배열(Array) (0) | 2024.01.17 |
|---|---|
| [자료구조] 자바의 자료구조 개념 정리 - 2 (1) | 2024.01.10 |
| [자료구조] 자바의 자료구조(Collection) - 1 (2) | 2024.01.04 |
| [자료구조] 02. Tree (0) | 2023.03.27 |
| [자료구조] 01. 그래프 (0) | 2023.03.27 |